
6
6
Introduction to AWS GLUE
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to move data between data stores. It is a serverless service, which means that it will automatically provision and scale the infrastructure required to perform data processing tasks.
AWS Glue consists of three components
- Data Catalog: Data Catalog is a centralized metadata repository that stores information about data sources and targets, including schema and partition information.
- ETL Engine: An Apache Spark-based engine that performs the AWS ETL (extract, transform, and load) operations on the data. AWS Glue provides pre-built transforms, or you can create your own custom transforms using Apache Spark code.
- Jobs: The ETL process is defined as a job in AWS Glue. You can schedule AWS Glue jobs to run on a regular basis, trigger them based on events, or run them on demand.
AWS Glue works with various data sources and targets, including Amazon S3, Amazon RDS, Amazon Redshift, and various other databases and file systems.
It provides a simple and flexible way to move data between different data stores, perform the data transformations, and then process the data at scale.
Below example may help us to illustrate how AWS Glue could be used
Suppose you work for a retail company that has multiple data sources, including customer orders, product inventory, and website clickstream data. You need to combine and transform this data to generate insights for the marketing team.
Follow the below steps
You start by using AWS Glue's Data Catalog to create a centralized metadata repository that stores information about your data sources. You can easily import metadata from your data sources or manually create tables in the catalog. You create tables for each of your data sources, including schema and partition information.
Next, you use the AWS Glue with the AWS ETL services to perform the extract, transform, and load operations on the data. You create an AWS Glue job that reads data from each of the tables in the Data Catalog and perform transformations using pre-built transforms. For example, you might join customer orders with product inventory data to get insights into which products are selling well, or you might aggregate website clickstream data to understand how customers are interacting with your website.
Finally, you schedule the job to run on a regular basis, such as once a day or once a week. The output data is then stored in Amazon S3 or another data store of your choice, where it can be analyzed by the marketing team.
With AWS Glue, you were able to easily combine and transform data from multiple sources, and automate the AWS ETL process to generate insights on a regular basis.
Few ways to save money on AWS Glue jobs
- Use a smaller instance size: AWS Glue offers various instance types and sizes, with varying amounts of CPU and memory. Choosing a smaller instance size can significantly reduce your Glue job's cost.
- Optimize the code: Optimize your AWS ETL code to make it more efficient and reduce the job's processing time. You can do this by using the right data structures, applying data partitioning, and optimizing the algorithms.
- Use data compression: Using data compression techniques like GZIP or Snappy can help you reduce the amount of data transfer and storage required, which can save you money.
- Monitor the job logs: Monitoring the job logs and identifying any errors or issues can help you optimize the Glue job's performance and reduce the AWS Glue cost.
- Use reserved capacity: AWS Glue offers reserved capacity for those who want to commit to using Glue for a certain period. This option can help you save up to 50% on your Glue job's cost.
- Use spot instances: AWS provides a spot instance pricing model, which can help you reduce your AWS Glue job's cost by up to 90%. Spot instances are spare EC2 instances that AWS makes available at a discounted rate. However, keep in mind that using spot instances comes with the risk of instance termination when the spot price exceeds your bid price.
- Automate job scheduling: Using AWS Lambda or AWS Step Functions to automate job scheduling can help you save time and money by reducing the need for manual intervention.
How optimizing the code can save money on AWS Glue
Suppose you have a Glue ETL job that processes data stored in Amazon S3. The job reads the data from S3, applies some transformations, and writes the results back to S3. The AWS Glue S3 job is currently taking 6 hours to complete and is using an instance type with 16 vCPUs and 64 GB of memory, which costs $1.20 per hour.
To optimize the code and reduce the job's processing time -
- If the data in S3 is stored in a large number of small files, you could use partitioning to group the data into larger files based on a common attribute. This can reduce the amount of data scanned and processed by the Glue job, leading to faster processing times and lower AWS Glue costs.
- Choose the right data structures, like arrays or maps, to store your data which will help reduce memory usage and improve processing times.
- If possible, split the Glue job into smaller, parallel tasks that can be processed simultaneously. This can help reduce the overall processing time and allow you to use a smaller instance type, leading to cost savings.
- Optimize the transformations applied to the data to reduce the amount of processing required. For example, you can use filters to remove unnecessary data or reduce the size of the dataset that needs to be processed.
Data compression can help save money on AWS Glue
Suppose you have an AWS Glue ETL job that processes a large amount of data stored in Amazon S3. The data is stored in CSV format and takes up a lot of storage space in S3. The job reads the data from S3, applies some transformations, and writes the results back to S3.
To save money on processing costs, you can use data compression to reduce the amount of data that needs to be processed by the Glue job. You can use a compression format such as GZIP or BZIP2 to compress the data before storing it in S3.
Example of how you can use GZIP compression with AWS Glue:
- First, create a GZIP-compressed version of the input data using the following command:
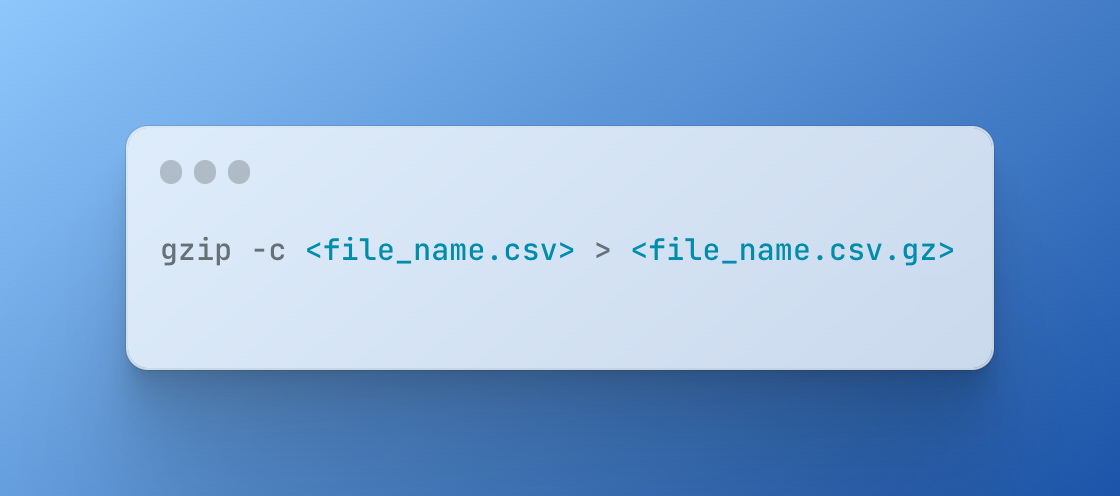
- Upload the compressed file to Amazon S3.
- Modify your Glue ETL job to read the compressed file from S3 and decompress it in memory using Python's built-in gzip module:
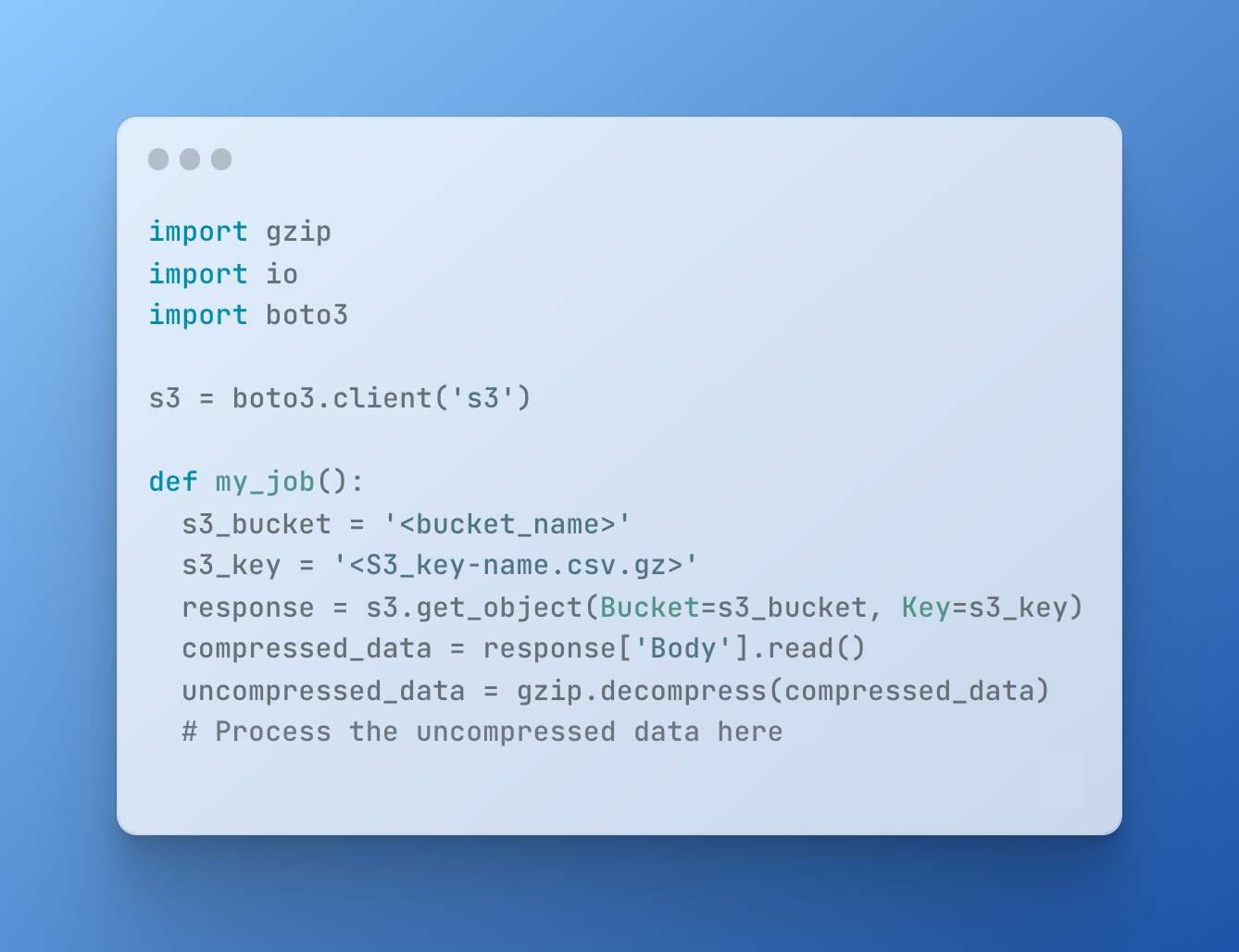
By using GZIP compression, you can significantly reduce the amount of data that needs to be read and processed by your Glue job. This can result in lower processing costs, as the job can be completed faster and require less memory and computing resources.
Monitoring job logs also helps in saving money on AWS Glue
Monitoring job logs is an important practice for optimizing AWS Glue ETL. By monitoring your job logs, you can identify issues that are causing your job to consume excessive resources or fail, and take corrective action to address these issues.
Examples of how you can monitor job logs in AWS Glue
Enable CloudWatch Logs

Flex Execution - AWS Glue provides functionality that can help us to save 35% of the costs of executing Spark jobs. By utilizing spare compute capacity for workloads and making it free for non-time-sensitive jobs, we can reduce the cost of jobs.
- Cost of running standard jobs is $0.44 per hour.
- Cost of running flexible jobs is $0.29 per hour, by which we can achieve 35% of savings
CloudKeeper helps you cost-optimize your entire cloud infrastructure and provides instant and guaranteed savings of up to 25% on your AWS bills. Talk to our experts, to learn more.









